如果近幾年來有在關注深度學習技術發展的話,一定有聽過 attention model 以及 Attention Is All You Need 這篇非常有名的論文,論文的細節這邊就不多談了,網路都可以找的到相當豐富的說明、實作。這邊主要要探討的是如何使用 attention 解決之前提到的輸入序列過長會導辨識效果不佳的問題。
Attention 的核心概念可以以下這句話來描述:
Attention: At different steps, let a model "focus" on different parts of the input.
Attention 機制的加入,會讓 decoder 在解碼的過程中找出輸入序列中哪些部分較為重要,因此 encoder 不需要再將輸入序列壓縮成一固定大小的 context vector。
而 decoder 中的每一個 hidden state 都會有不同的 context vector,也就是說如果輸入序列有 N 個音框(frame),就會產生 N 個 context vector。接下來我們用數學式子來表示 attention 的運作過程:
all encoder hidden states:
decoder hidden state at timestamp t :
Attention weights: 將目前時間點 (timestamp) decoder 的 hidden state 對所有 encoder 的 hidden state 進行 score function,再透過 softmax function 計算出
對每一個時間點
的重要程度
其中score function 的運算方式有好幾種,包括 dot-product, bilinear, multi-layer perceptron 等
Context vector: 將 attention weights 與 encoder hidden state 進行 weighted sum
完整流程架構可以參考下圖: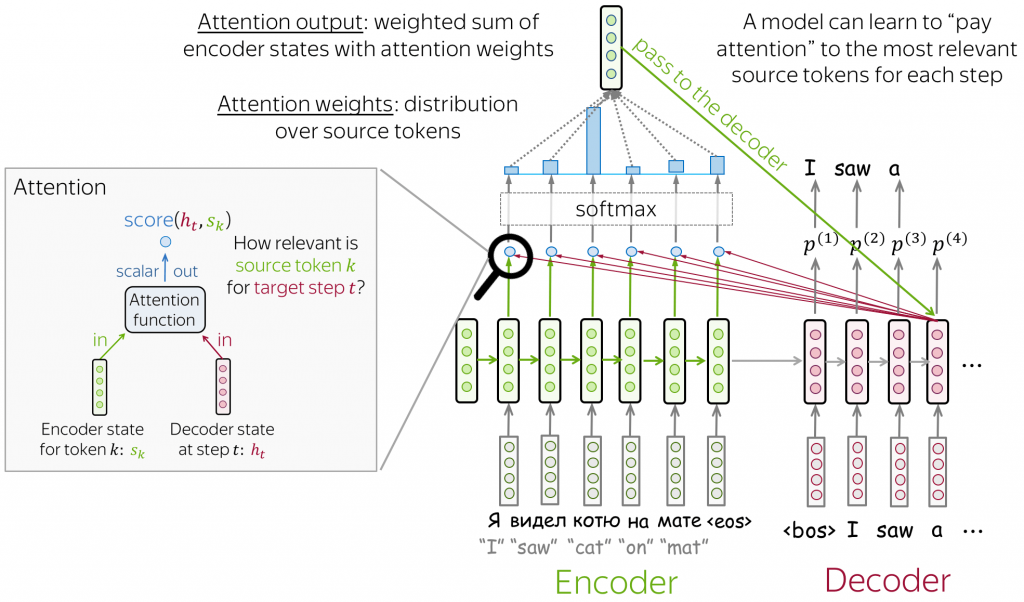
Seq2seq attention 架構圖,圖片來源: https://lena-voita.github.io/nlp_course/seq2seq_and_attention.html
今天的內容就到這邊,接下來會介紹之前有提到過的end-to-end model 中另一個方常見的方法 -- Connectionist Temporal Classification (CTC)。
參考資料: https://lena-voita.github.io/nlp_course/seq2seq_and_attention.html

